Blend2D cannot be maintained nor developed without funding! Please visit the Funding Page for more details.
About
Blend2D is a high-performance 2D vector graphics engine written in C++. It was written from scratch with the goal to achieve the best possible software-based acceleration of 2D rendering. Blend2D provides a high-quality and high-performance analytic rasterizer, a new stroking engine that uses curve offsetting instead of flattening, a 2D pipeline generator that uses JIT compilation to generate optimal 2D pipelines at runtime, and has a capability to use multiple threads to accelerate the performance even further.
The library was also written with zero dependencies in mind. Currently, it only depends on AsmJit, which is used for JIT compilation. All features that Blend2D provides are implemented by Blend2D itself, including image loading capabilities and text rendering (freetype or operating system provided libraries are not used).
The Team
Blend2D project is developed by the following people:
- Petr Kobalicek (2015 to present) - Project founder and lead developer
- Fabian Yzerman (2018 to present) - Geometry and curve offsetting
Contact Us
- Support Page - Contact and support options
- Public Chat - Public Blend2D chat on Gitter
How to Join?
There are currently no rules about becoming part of the Blend2D Team. We think that anyone interested in Blend2D development should contribute first by opening issues, pull requests, by joining our channels, and by promoting Blend2D on other sites in a neutral way. Anyone who starts making significant contributions that match our code quality will be offered to join Blend2D project at some point.
History
The Blend2D project started in 2015, as an experiment to use a JIT compiler for generating 2D pipelines. The initial prototype did not use any SIMD and was already faster than both Qt and Cairo in composition of the output from the rasterizer. It was probably not just about the pipeline itself as the rasterizer was already optimized. However, the rasterizer was much worse than the one used today. The prototype was initially written for fun and without any intentions to make a library out of it. But the performance was so impressive that it built the foundation of Blend2D.
2015-2019 - The Way to Beta
After the evaluation period it was obvious that Blend2D competes very well with other 2D renderers in terms of performance while maintaining the same rendering quality. This was the motivation to implement gradients, textures, and advanced composition operators. Yet it was uncertain which features the library should provide in the first place. Because of the high complexity with text rendering in general, the initial idea was to only create a library that is able to render vector paths, so the burden of converting text to paths would be on Blend2D users. Finally, it became clear that a 2D rendering engine without native text support is not practical, so the idea of having basic support for TTF and OTF fonts has been explored and finally implemented.
After basic text rendering was implemented, two more ideas were pursued: Faster rasterization and a better stroking engine that would be able to offset curves without flattening. The work on the rasterizer started in late 2017 and took around 3 months to complete, with some extra time to stabilize. Around 20 variations of different rasterizers have been implemented and benchmarked so that the best approach for Blend2D was chosen and further refined. Research into the new stroking engine started in 2018 and also required a few months of studying and experimenting before the initial prototype was implemented. Although not considered initially, because of positive results, the new stroking engine has been added to the beta release of Blend2D.
The most important features planned for a beta release were finalized in early 2019 and it became clear that with some additional bug fixing and testing it would be possible to release Blend2D beta around March 2019. Blend2D was finally released to the public on April 2nd, including code samples and a benchmarking tool.
2020-2022 - Multithreading & Optimizations
In the early 2020 a work on multi-threaded rendering context has begun. It took approximately 3 months to design and implement the initial prototype that was on par with features provided by the single-threaded rendering context. It was committed to master branch in April 2020 and released as a part of beta13 release. Blend2D was most likely the first open-source 2D vector graphics engine that offered a multi-threaded / asynchronous rendering.
After the multithreaded rendering has been implemented the focus shifted on optimizations. More optimizations were added to take advantage of AVX2 and AVX-512 instructions in the JIT compiler and more serious work has been put into A8 pixel format support. During the period of 2020-2022 many bugs were fixed and many new optimizations added to take the advantage of the most recent X86_64 hardware.
2023 - Render Call Dispatching & Gradient Dithering
In 2023, the dispatching mechanism of the rendering context has been completely reworked to allow passing styles explicitly to avoid calling set_fill_style() and set_stroke_style(). In many cases this makes the user code simpler and also faster. It was profiled that calling these functions accounted for roughly 5% of CPU cycles during stress tests that focused on filling small rectangles. This change improved the performance of these workloads and cleaned up the the implementation of the dispatching mechanism in the rendering context. One interesting thing to note here is that Blend2D uses a completely table-driven approach to compute the most important information required for selecting the right pipeline based on the source style, composition operator, and destination pixel format.
In addition, the possibility to dither gradients was added to Blend2D, which is turned off by default.
2024 - AArch64 JIT & Stability
2024 is the year of AArch64 JIT. Blend2D's JIT compiler was successfully ported to AArch64 architecture via a new abstraction layer that targets both 32/64-bit X86 and 64-bit ARM (AArch64). Thanks to such abstractions porting the JIT compiler to more CPU architectures should be much simpler from now provided that they are supported by AsmJit first.
In addition, focus also shifted on stability and a new test suite was developed to ensure pixel identical output of portable and JIT pipelines, which should ensure that all code paths that the JIT compiler can take are correct. The reason is that some past bugs have shown us that developing & testing on the most recent CPU micro-architectures would not ensure stability on older hardware if a separate code path is taken for the recent one. In that case a bug could go unnoticed for a long time as the code would not execute on most machines. As a result, Blend2D can now verify that all code paths used by X86 (from SSE2 to AVX-512) and ARM64 generate correct pipelines.
FAQ
Please take some time and read our FAQ to learn a little more about the questions people often ask. You are welcome to contact us if you need more details or if you would like to ask us something we have missed.
Isn't Blend2D Architecture Specific?
The only architecture specific code in Blend2D is a JIT pipeline compiler, which can currently target X86, X86_64, and AArch64 architectures. The rest of the code is portable C++ with optional optimizations that use compiler intrinsics to take advantage of SIMD or other general purpose ISA extensions. Experimental pipeline that doesn't use JIT is under active development and even now it's possible to use it on platforms where JIT is not available.
It's worth mentioning that architecture-specific optimizations are used by many mainstream 2D rendering engines that offer a software-based backend, because SIMD can significantly improve the performance of per pixel calculations. Blend2D's JIT compiler uses a lot of abstractions so a single code path can be used to target multiple architectures with the possibility to use architecture dependent code where it offers benefits.
Does JIT Compilation Have a Startup Cost?
Blend2D uses AsmJit's Compiler tool to generate JIT pipelines at runtime. AsmJit can generate over 100 MB/s of machine code on most mainstream machines and more than 200MB/s on the recent X86_64 and AArch64 hardware. Most 2D rendering workloads only require few pipelines that may need about 20-50kB of memory as the size of a single pipeline varies between 0.2kB to 5kB. Pipelines are cached and never generated twice. The required time to create a pipeline is negligible (typically a fraction of a millisecond) compared to the time spent by executing it.
We haven't experienced any kind of startup delay in Blend2D demos nor during benchmarking. Users that use Blend2D library in production also never mentioned any kind of delay that would be noticeable when rendering the first frame.
Is Multi-Threaded Rendering Beneficial?
The performance of multi-threaded rendering highly depends on the size of the target image and on the actual render calls. Multi-threaded rendering (also called asynchronous rendering in Blend2D) serializes all render calls to a command queue, which is then executed later by workers. Each worker acquires a band, which consists of several scanlines, and processes all commands within that band before acquiring another band. This approach is very beneficial when rendering into a larger image (FullHD, 4K), because each band is processed only once, thus it can remain in the CPU cache for all commands that intersect such band. This approach is also great for worker threads in general as it's guaranteed that worker threads do not need any synchronization as they don't share pixels of target image - once a worker acquires a band no other thread can acquire it.
The performance page clearly shows advantages of multi-threaded rendering in all tested scenarios, but how beneficial it would be for a particular workload would have to be benchmarked separately. Blend2D demos that use Qt library have the ability to select a multi-threaded rendering engine so such demos can also be used as a reference to compare the performance of various implementations (including Qt). It's worth mentioning that worker threads are not fully utilized in these demos, which means that they are usually clocked lower than the main thread. We cannot do much about this as those demos use Qt, which is responsible for blitting the framebuffer into the GPU memory, and this operation seems synchronous.
Please note that the current implementation is still a prototype that will be improved in the future, we think we can make multi-threaded rendering even more efficient.
How Blend2D competes against GPU Rendering?
The Blend2D project started as a challenge to compete with existing software-based 2D renderers in terms of raw performance. It's very difficult to state whether CPU or GPU is better without actually comparing a specific CPU vs a specific GPU and visual outputs of both. SVG tiger is usually provided to showcase the performance of 2D rendering libraries and we have only done a limited comparison against Vello, which is an experimental 2D GPU renderer written in Rust. The image below showcases Vello vs Blend2D on a Ryzen 7950X machine that uses integrated GPU:
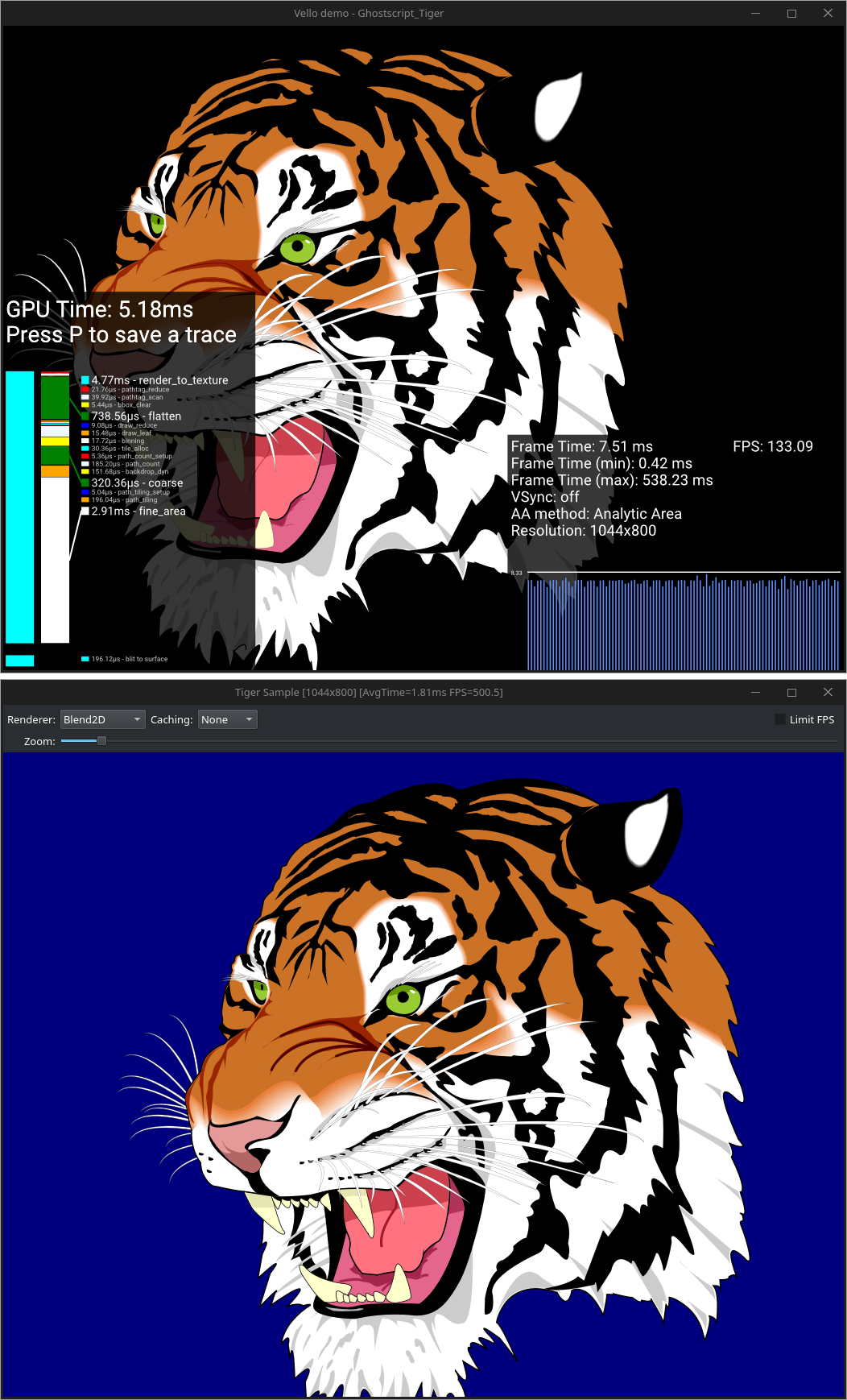
On the tested machine Blend2D that uses CPU (single thread) is faster than Vello that uses GPU, but this result alone cannot be used to draw any conclusions, because it's just a rendering time, which doesn't include any other metrics such as power draw. In addition, Vello does much better on Apple Silicon that has a much faster GPU. For example on Apple M3 Vello can render the same Tiger close to 0.5ms, which is basically an order of magnitude faster than using the Ryzen 7950X iGPU. Blend2D needs 1.5ms to render the same tiger on Apple M3 by using a single thread and 1ms when using two threads.
We consider this question open and we would like to provide more testing in the future. However, we would like to stay in the CPU rendering world at the moment as there is still a lot of areas in Blend2D we don't consider optimized. GPU rendering is something we would like to explore once we consider the software rendering done.